今天是端午假期,没有出去玩,正好也有点时间来写写东西。这次我们介绍的是一个字符串相似度算法,它可以作为两个事物关联匹配中的一个因素。请听我慢慢道来。
莱文斯坦距离(LD)用于衡量两个字符串之间的相似度。 以下我们称这两个字符串分别为a和b。莱文斯坦距离被定义为"将字符串a变换为字符串b所需的删除、插入、替换操作的次数"。
莱文斯坦距离以俄国科学家Vladimir levenshtein命名,他于1965年发明了这个算法。 如果你对Levenshtein这个词的发音有问题,也可以称这个距离为编辑距离。
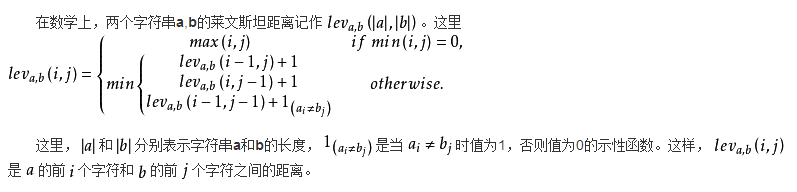
莱文斯坦距离至少是两个字符串长度的差值
莱文斯坦距离不大于较大的那个字符串的长度
如果两个字符串相等,那么它们的莱文斯坦距离为0
如果两个字符串等长,那么它们的汉明距离是莱文斯坦距离的上界
两字符串的莱文斯坦距离不大于它们与第三个字符串的莱文斯坦距离之和(三角性)
以上都是百度查的资料,哈哈
莱文斯坦距离是很有作用的,举个例子,现在需要匹配两个酒店是否为同一个酒店,首先肯定是根据酒店名称,酒店地址等信息来作为匹配条件。如果酒店名称一样,地址也一样,那肯定就是同一个酒店,如果相似度都不一样,那还得根据其他因素来确定,比如电话,经纬度等。
废话不多说,上代码。
import Levenshtein
a = u'我是莱文斯坦距离'
b = u'我是莱文斯坦比'
print Levenshtein.ratio(a, b)
结果如下:

可以看出来,他们的相似度为0.8。最近在做一个微信机器人,用了就是简单的莱文斯坦算法,当相似度大于等于0.8时就认为是该命令,当然这个只是一个很初级的东西。后续得加上各种因素,把它等价于一个数学函数,相似度算法只是其中的一个影响系数,还有其他等等的系数,最后就是求最优解。人工智能这条路很远,也很有意思,让我们共勉,再接再厉。