我以为弄完ip池的问题就可以轻松一下了,没想到刚刚睡好觉一个晚上,又遇到了一个问题。
事情是这样子的,最近需要下载差不多60W的酒店图片数据,算起来差不多磁盘占用的空间需要14T这样。
文件一大,存储的方式就得很注意,不懂大家有没有发现windows一个文件夹的文件或者文件夹数量当大于到一定数量的时候就会很卡。这是因为每次访问文件夹的时候,windows会建立起索引,得循环遍历一次。可想而知如果把这么大的数据量保存在同一个文件夹里面,没有更具体的目录的话,访问都是一个很大的问题。
这个只是其中一个问题,这么大的数据量的下载,网络带宽肯定也是一个瓶颈,你也许会说,就让它慢慢下载吧。那当然可以,但是既然我们做了,就得做到最好。这里我想了一个分布式的方案。
分布式的队列方案,我采用的是redis,我曾经在rabbitmq跟redis之间徘徊循环了很久。工具没有好坏,只有哪个更加适用哪个场景。这里的情况,redis明显更好。
- 1.当redis push的数据量小于10K的时候,速度会是rabbitmq的好几倍.第一个秒杀.
- 2.redis pop 无论数据量大小(在我的测试范围内的大小-10K左右),速度都比rabbitmq速度优异。
简单的总结一下rabbitmq跟redis的使用场景。一般在web场景下,都是使用redis,要的就是性能,轻量级,并发。比如api。而rabbitmq适合用于大型复杂的项目中使用,因为它支持超级多协议:可靠消息、队列监控等。
回到正题。下载之后的图片我们得汇总,记录其所在的位置,可以分布在不同的服务器,或者到同一个服务器,看需求。但是我们必须把它标记,记录它的存放位置。
经过上述的描述,我们可以总结出,我们需要处理的几个问题。
- 1.文件夹创建方式
- 2.文件的下载-借用redis作为队列实现分布式下载
- 3.文件的标记
- 4.文件的汇总
文件夹的创建
目前我们的酒店是60多W,也就是有60多W的文件夹。我这里采取的方式,将酒店的唯一标识id取其hash。
import hashlib
conetnt = hashlib.sha1('7892470').hexdigest()
print conetnt
print conetnt[0:1]
print conetnt[1:2]
print conetnt[2:3]
print conetnt[3:4]
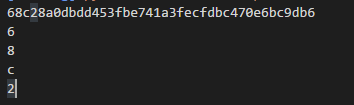
每一位hash都是由0-9还有a-z,一共36可能组成的。那我们大致可以算下。36的4次方就是1679616种可能。每个目录最多36个文件夹,这样子就可以解决我们分目录的问题。而且留下规律为我们之后的汇总给予支持。
文件的下载
首先,我们需要将我们需要处理的数据刷进redis的list。
def add_data(self, content):
RedisDB.spider().lpush('list:hotels', content)
以上是我封装的一个方法,获取redis链接,大家可以自行封装。
接下来要做的就是我们的下载程序,从redis中获取一条需要处理的数据进行图片的下载。
def get_data(self):
return RedisDB.spider().lpop('list:hotels')
def down_img(self,url,path):
stream = urllib2.urlopen(url).read()
with open(path, "wb+") as f:
f.write(stream)
文件的标记
因为我们是根据hash来分配文件夹的,所以我们只需要记住它在哪个盘以及下载的图片的id以及后缀名就行。
{
"ids": [
"26680713.jpg",
"31618341.jpg",
"31618336.jpg",
"31618320.jpg",
"31618318.jpg",
"31618316.jpg",
"31618314.jpeg",
"31618310.jpeg",
"31618305.jpeg",
"31618301.jpeg"
],
"path": "D:/image"
}
接着把我们的这个路径给保存起来。我这里只是简单的说下,因为我下载的图片里面还得具体的区分好几种目录,比如封面、外观、内部、用户评价等。也是这样子的方式,扩展下规律存取就行。
文件的汇总
为什么会有文件的汇总,因为我这里虽然是分布式下载的,但是最后还是希望保存到一个硬盘里面。汇总的话,其实就是一个复制的过程。但是这种小文件的复制,其实也很慢。解决的办法,进行压缩,然后容量尽量不要太大。到时候拷过去之后直接解压。
说个题外话,最近我想发起一个全公司一起下载的计划,这样子就解决了多台服务器的问题,每个同学都领一部分的任务回去下载,python打包好程序,并且做好标记。一下子就把任务全部分解开,而且速度相当快,现在小区的带宽都已经飙到2000M光纤甚至更高了。就是利用大家的空闲资源,并且给予一定的回报,毕竟自己部署服务器买带宽,这个也是一个不小的投入。花在员工身上,何乐而不为呢。该想法其实在市面上已经有很多的应用了,只是你没有发现。比如某些下载器,在你下载的同时,也把你当做服务器给其他台机子传递信息。还有某盒子,开的越久钱赚的更多,其实也是利用了你的网络资源。还有。。。。
说到这里,大致的思路我们是说清楚了。其中还有许多细节需要大家去完善,我这里只是说个大概,这次的源码就不发布了。其实在写python之前,我是一个写api的,用的是其他语言。但是写了python之后,我才知道它的强大,以致现在无法自拔,完全被它吸引。人生苦短,各位看官,请用python。
我想今晚我应该可以睡个好觉了。