天气这么热,人的思路感觉都会有所阻塞。之前说过会做一个最优惠机票酒店之类的推荐,那么就要广大的收集各方面的资源。今天呢,就专门花了点时间,把去哪儿的接口给一探究竟。
故事背景
故事发生在上周五下班之前,我呢,习惯性的检查下各个服务器的程序是否正常的在运行。
打开某台服务器的时候,惊讶的发现,一台服务器的运行的程序,怎么都是一直出现not data。。。
心里一慌,这api看来不能用了。
于是打开工作日志查看相应接口,copy到浏览器中访问,结果 status:400 msg: bad request。
好吧,刚刚乐几天,你又改接口了。
于是打开网页一看,果然之前的api已经替换,换成新的api,加密规则也变了。然后习惯性的F12,查找js资源,查看api等。
也许是园区6点就关空调的原因吧,现在已经是7点10分了,我想下班(因为实在是太热,开窗户都很热的)。。。,但是没搞定,我今晚肯定睡不着的。
纠结挣扎了许久,我做了一个很机智的决定,这么热的天气非常影响思路,不如放松一下,可能会有不同的效果。
所以收工,此时已经8点10分。
分析过程
休息了两天,思路果然完全不一样。早上十点到公司,电脑一解锁,就立马开工起来。如果我没回忆错的话,到完成之前,我没有喝过一口水。一旦进入状态,完全就是鸡血模式。
确定请求接口
F12,切换到XHR,只看请求接口,会发现如下图的接口。
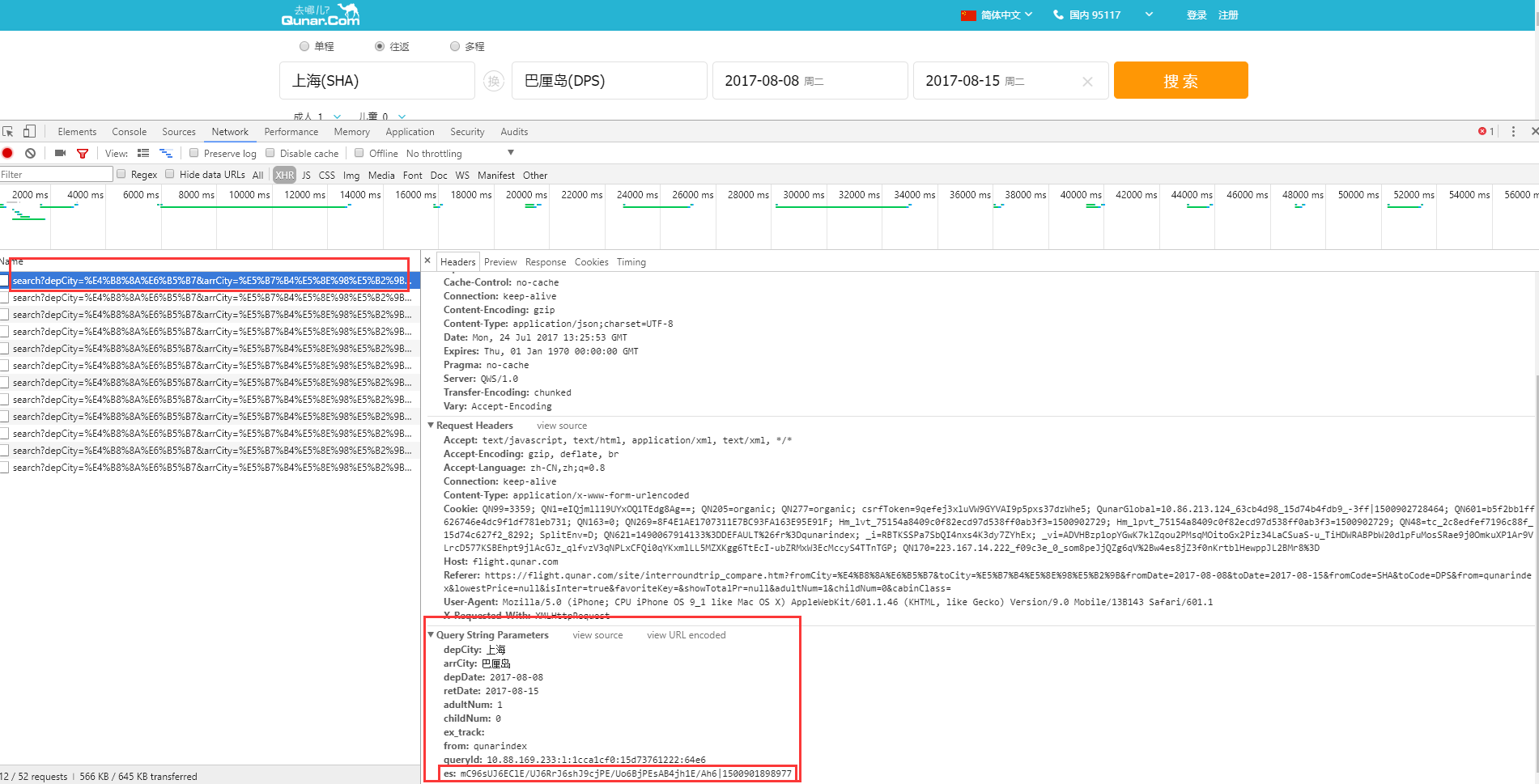
请求方式get、携带搜索日期、地点、成人数量、小朋友数量、来源、请求id等参数。
猜测 es就是我们所需要的加密信息。
寻找获取此接口的js代码(化功大法)
为什么会说是化功大法。
1.网站有许多的js代码,几千行,甚至几万行。
2.js代码大部分都是压缩的,肉眼看过去都是一堆类似于乱码的英文。
大家可以借助各种工具来进行统一搜索。。。。找的过程这里不详细说明,省略。。。。
最后发现其实这个接口的请求js代码就在它的页面上,不过是压缩之后的。如下图:

我放在notepad++里面解压查看,需要安装jstool这个插件。
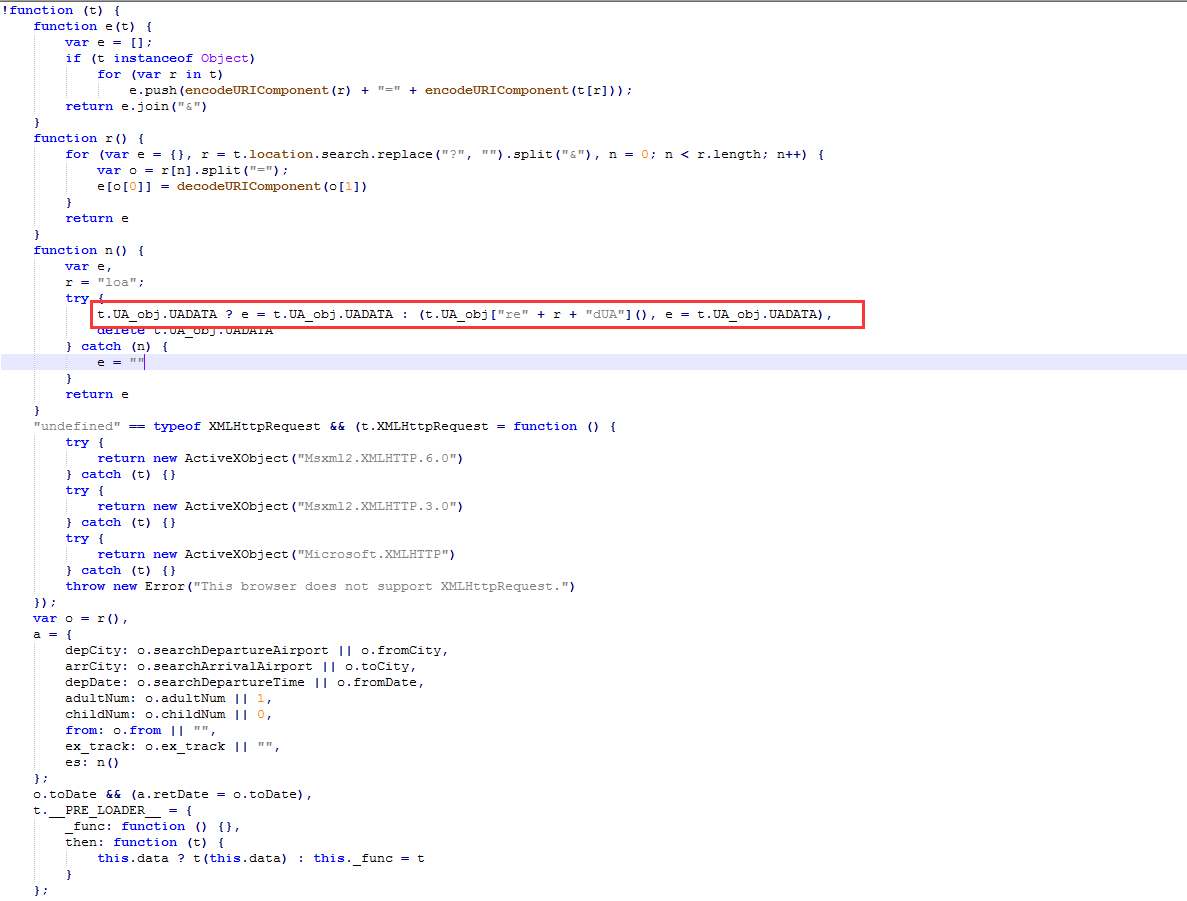
发现其实它是在window对象中注入方法以及加密串。也就是说,你需要访问页面才可以拿到这个信息。
有些小伙伴可能会说,那直接找到加密方法,加密参数,直接进行加密方法的破解,不就可以了嘛。
对的,你非常聪明,我也是想这么做的,但是后面发现,它的这个加密信息是随时有可能变的,也就是你的加密方法也要一直变化(为什么是一直变化的,我下面会说)。
那有没有一劳永逸的办法呢,答案是有的,借助我们的selenium,模拟浏览器操作,注入获取密码的js代码,拿到保存在一个地方。当它失效的时候再请求一次,或者主动的定时去刷新,都是可以的。
如果有兴趣了解它的加密方法的小伙伴,我跟大家说下他的加密方法在哪里。通过上面一个获取es参数的js代码我们知道,它是放在window里面的,那么我们把它拿出来看看。

竟然包含了版本号,其实是个时间戳,还有加密参数还是小写的uaDATA。真正的是大写的UADATA,看代码可以知道,它生成完了之后就删除了。(但是我还是可以拿到啊,哈哈。。。)
reloadUA是一个方法,我们右键进入js代码块。

还是一个压缩的js代码,我们copy一下放到notepad++出查看。发现这个时候它调用的是里面的一段叫_hqc的函数。有兴趣的小伙伴可以研究下它的加密方法。
它这个请求文件是随着页面变化的,也就是说你下一次刷新的时候请求的也许就不是这个js加密代码了(根据观察有效时间服务端应该是控制在半小时左右)。
到这里我们就大概把js给分析完毕了。
模拟真实浏览器进行es的获取
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
class FlightSign:
def _get_desired_capabilities(self):
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = (
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0"
)
dcap["phantomjs.page.settings.loadImages"] = False
return dcap
def _get_sign(self, date, depart, destination):
dcap = self._get_desired_capabilities()
driver = webdriver.PhantomJS(desired_capabilities=dcap)
driver.delete_all_cookies()
driver.set_page_load_timeout(30)
driver.set_script_timeout(30)
url = (
'https://flight.qunar.com/site/oneway_list_inter.htm?searchDepartureAirport=%s&searchArrivalAirport=%s'
'&searchDepartureTime=%s&adultNum=1&childNum=0' %
(depart, destination, date))
driver.get(url)
es = driver.execute_script(
"return (window.UA_obj['reloadUA'](),window.UA_obj.UADATA)")
driver.quit()
return es
def start(self):
print self._get_sign('2017-08-08', u'上海', u'巴厘岛')
if __name__ == '__main__':
FlightSign().start()
一个小小的demo,思路是:
1.查找8月8号上海到巴厘岛的路线
2.使用phantomjs来请求数据,之后注入获取es参数的js代码
3.输出密钥
一些方案的探讨
1.直接破解加密方法确实是一个好办法,但是这个js加密代码是随着页面变化而变化的,也就是说你破解了一次之后,人家要是变了你还得随时去修改加密算法,得不偿失,太浪费时间。使用selenium的好处,只要你加密方法不变,那就可以一直用,算是一劳永逸。
2.由于查询的数据量偏大,及时性要求很高,需要把往返(2)、天数(90)、航线(5000多)在半小时之类更新完毕。最好的方式就是分布式获取。PhantomJS我用的服务器,请求一次可以控制在2秒以内。大家看下自己的需要,然后需要分布式几台。
总结
最近有小伙伴问我,我到底是做什么的。怎么api也写,cms也写,连爬虫也做。好吧,其实我是在做人工智能的一个小模块。通过大量的基础数据分析,得出一系列的结论帮助公司运营。这个当然只是很小的一部分,最重要的是通过一定的算法,策略,来自动化的运营,减少人员的投入,提高公司的竞争力。那就需要各个方面都需要涉及到了,有了数据,那自然会提供服务,那就有了api。也会提供操作后台,那就有了cms。分析竞品,那就有了爬虫。就差没有写专业的外站了。。。。
其实爬虫与反爬虫的斗争向来是无法停止的,正所谓道高一尺魔高一丈。我坚信一个规则,只要你的东西是展示出来给用户看的,那么我一定有办法拿到,即使你的反爬虫多么及时有效。
破解反爬虫的唯一真理,让它认为你是一个真实的用户在查询。