今天跟大家介绍一下哈希一致性的原理。
说到哈希一致性,想必有写过api、连接池的小伙伴都会遇到,对其印象也非常深刻,如何把有效的资源最大程度上进行均衡分配,也就是大家口中所说的负载均衡。
著名nginx的负载均衡也是基于哈希一致性原理所实现的。
进入正题,文章会分先后顺序进行,先以简单的方式讲解,之后进行图文说明,最后附上python实现的代码块。
简单讲解(两分钟所在地)
普通: 比如有11个需要存储的数据,有3台服务器,按照取模的方式进行分配的话,就是:
node 1:1 4 7 10
node 2:2 5 8 11
node 3:3 6 9
如果这个时候新增1台服务器,那结果就变成如下方式:
node 1:1 5 9
node 2:2 6 10
node 3:3 7 11
node 4:4 8
这样子做的话,需要迁移的数据量就大了,除了1、2、3没有变化,其他存储的位置已经发生了改变,迁移成本大
哈希一致性:
实现原理:对于需要处理的数据与服务器都进行一次哈希计算,数据与服务器哈希最相近的节点作为存放节点,如此就可以保证当节点增加或者减少的时候,影响面最小。
假设以下的代表着数据与起对应的哈希值(哈希值不准确),为了方便讲解:
1:196 2:200 3:204 4:208 5:212 6:216
7:220 8:224 9:228 10:232 11: 236
3台服务器的哈希值: node 1:207 node 2:218 node3:230
比较方式如下,如果大于230的,就归到207,这样子的话,就形成了一个环(哈希环),结果如下:
node 1:1 2 3 10 11
node 2:4 5 6
node 3:7 8 9
这个时候新增一个节点 node 4:225 结果如下:
node 1:1 2 3 10 11
node 2:4 5 6
node 4:7 8
node 3:9
可以看到这个时候只改变了7-8的位置,但是你肯定会问一个问题,这样子不是均衡分配啊,只是保证数据改动的少,所以还得考虑到一个平衡性问题。
也就是所谓的虚拟服务器节点的概念,后面详细解释会说到。
图文讲解
通过以上的讲解,我想大家对哈希一致性算法有了比较深刻的理解了,现在再来详细的说明下,相信就会完全了解其原理。
首先哈希一致性算法讲究的其实是四个条件,均衡性、单调性、分散性、负载。
今天这里呢,就讲解下均衡性与单调性。
单调性:如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲区加入到系统中,那么哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲区中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
上面的例子讲解的其实就是单调性,接下来我会以图文形式进行说明,加强下理解。
1.hash环
一般来说hash算法都是将value映射到一个0~2^32-1次方的数值空间。(为什么要说这个数值,是为了跟下面的图片形成对应,图片抄袭于网络,省事,如果侵权,请告知,立马删除) 
2.进行服务器节点的锁定
4个服务器节点,分为为hash(object1)=key1 ... hash(object2)=key2 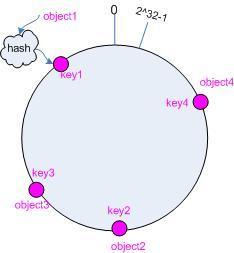
3.进行缓存的插入
假设有3个缓存,hash(cache A)=key A、hash(cache B)=key B、hash(cache C)=key C
寻找最近距离的原则,就形成了以下的结果。 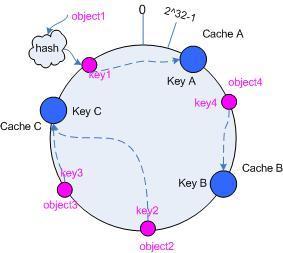
4.删除或者新增一台服务器
假设现在需要删除一个服务器object2,那原来的cache B就需要根据规则,往object1或者object3移动。而不需要移动原来的cache A、cache C.
假设现在新增了一台服务器object4,那变化也不会大,仅仅是在object4附近的cache B向左或者向右靠近。
均衡性:平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
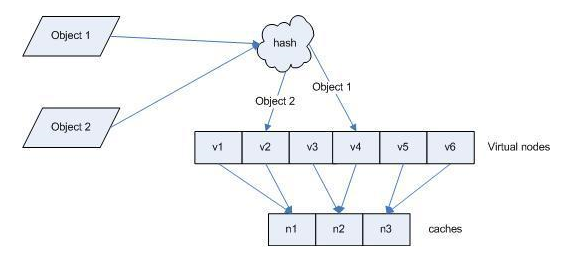
大概可以看到以上的算法并不是均衡的分配,只是强调了单调性,所以为了解决这个问题,会引入一个叫虚拟节点的概念,什么是虚拟节点,就是在原来服务器上的节点下,再延伸出子节点。
代码块
# encoding:utf-8
import md5
class HashRing(object):
def __init__(self, nodes=None, replicas=3):
'''初始化 hash环,即一致性哈希 一些参数
'''
self.replicas = replicas
self.ring = dict()
self._sorted_keys = []
if nodes:
for node in nodes:
self.add_node(node)
def add_node(self, node):
'''新增一个节点
'''
for i in xrange(0, self.replicas):
key = self.get_key('%s:%s' % (node, i))
self.ring[key] = node
self._sorted_keys.append(key)
self._sorted_keys.sort()
def remove_node(self, node):
'''删除一个节点
'''
for i in xrange(0, self.replicas):
key = self.get_key('%s:%s' % (node, i))
del self.ring[key]
self._sorted_keys.remove(key)
def get_node(self, string_key):
'''获取一个节点
'''
return self.get_node_pos(string_key)[0]
def get_node_pos(self, string_key):
'''获取节点以及位置
'''
if not self.ring:
return None, None
key = self.get_key(string_key)
nodes = self._sorted_keys
for i in xrange(0, len(nodes)):
node = nodes[i]
if key <= node:
return self.ring[node], i
return self.ring[nodes[0]], 0
def get_nodes(self, string_key):
'''ip池迭代器
'''
if not self.ring:
yield None, None
node, pos = self.get_node_pos(string_key)
for key in self._sorted_keys[pos:]:
yield self.ring[key]
while True:
for key in self._sorted_keys:
yield self.ring[key]
def get_key(self, key):
'''获取一个16进制的long md5
'''
m = md5.new()
m.update(key)
return long(m.hexdigest(), 16)
if __name__ == '__main__':
import time
ips = ['1', '2', '3', '4', '5', '6']
ring = HashRing(ips, 10)
timestamp = int(round(time.time() * 1000))
print ring.get_nodes(str(timestamp)).next()
总结
哈希一致性的使用范围非常广泛,各种主流的集群、负载均衡,都是依赖此原理延伸出来的算法。平时你用redis的集群、nginx的配置或者使用别人写好的ip池、连接池的类库,都已经很方便的实现了。 这个文章主要是讲解了其中的原理以及python实现哈希一致性的例子。