业务场景:
1.N个关键词的搜索结果:app列表 例子: 搜索词:tuox 结果: ['app1','app2','app3']
2.现更新机制:每天关键词未必会推送全量,需要对不变的数据,进行继承
3.求: 1).每个app的全部、top3的关键词覆盖数(搜索结果存在该app,即为覆盖)2).每个app的覆盖列表的展示(排名变动则更新)
实现这种场景:
一般想到的就是每天一张表,第二天凌晨进行数据的快速备份,接着进行数据的更新
备份有很多种方式:
1.程序脚本手动更新
2.binlog实现(使用最多的方式)
但是备份会带来很多的问题: 1.备份的不稳定性 2.备份到成功之间的时差所产生的数据更新写入的失败 3.极其庞大的存储空间
方案初探:
那有没有一个完美的方案,答案是有的,那就是拉链表
什么是拉链表
维护历史状态,以及最新状态数据的一种表,拉链表根据拉链粒度的不同,实际上相当于快照,只不过做了优化,去除了一部分不变的记录,通过拉链表可以很方便的还原出拉链时点的客户记录。
拉链表的场景
1.数据量比较大。
2.表中的部分字段会被更新,比如用户的地址,银行利率,订单的状态等。
3.需要查看某一个时间点或者时间段的历史快照信息,比如,查看利率在历史某一个时间点的状态。
4.变化的比例和频率不是很大,比如,总共有1000万的会员,每天新增和发生变化的有10万左右。
5.如果对这边表每天都保留一份全量,那么每次全量中会保存很多不变的信息,对存储是极大的浪费;
拉链历史表,既能满足反应数据的历史状态,又可以最大程度的节省存储。
方案思路:
通过拉链表解决了历史记录备份的问题,但是我们还有面临的挑战:1.更新量大的问题 2.需要对结果的排名进行排序 3.需要对历史记录进行聚合汇总结果
技术选型:es: 存储历史记录 tendis: 采用string类型,进行每个关键词对应的每个app最新的记录
es存储的记录为: _id: '%s_%s_%s' % (word_id,app_id,start_date) _doc: word_id、app_id、rank、start_date、end_date
tendis最新记录: key: '%s_%s' % (word_id,app_id) value: rank、start_date、end_date
很多同学肯定会认为:为什么要用tendis,目标是什么?
其实目标很简单,就是通过kv这种nosql的性能库来解决(redis内存太贵,数据量非常大),频繁在es中搜索当前最新的一条数据的过程,加快程序的计算,这样子es只会进行处理更新与插入的数据以及页面的简单查询,减少压力
接下来让我们看一下方案的逻辑图
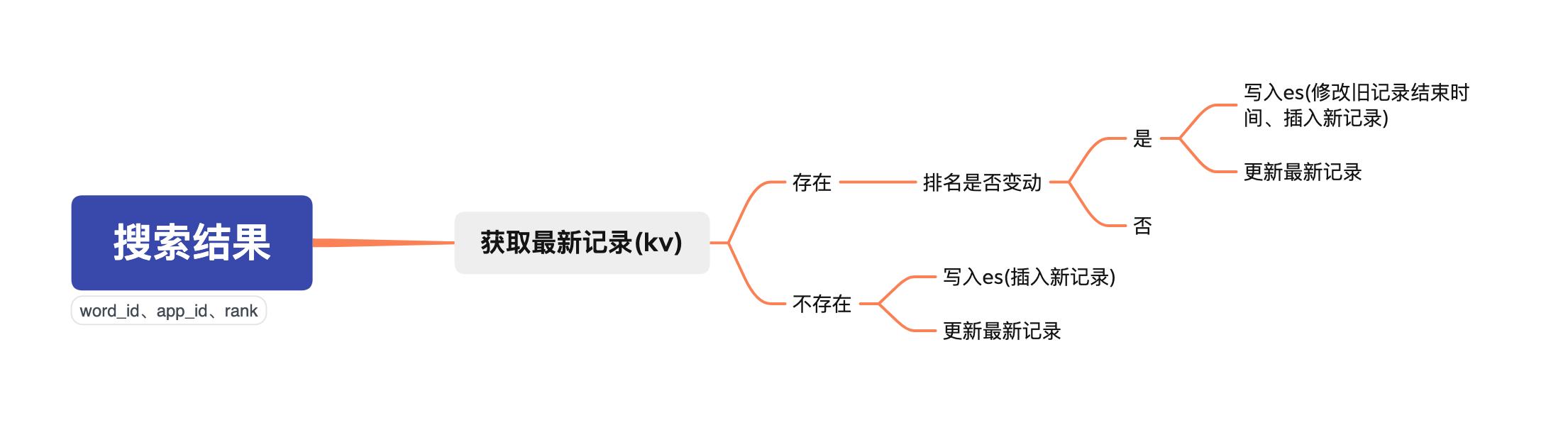
部分伪代码:
1.创建mapping
mapping = {
'properties': {
'app_id': {
'type': 'integer'
},
'word_id': {
'type': 'integer'
},
'rank': {
'type': 'integer'
},
'start_date': {
'type': 'date'
},
'end_date': {
'type': 'date'
}
}
}
es_index = 'search_result'
2.查询语句
{
"query": {
"bool": {
"must": [
{
"range": {
"start_date": {
"lte": "2021-09-02T00:00:00"
}
}
},
{
"range": {
"end_date": {
"gte": "2021-09-02T00:00:00"
}
}
},
{
"term": {
"app_id": 1
}
}
]
}
},
"size": 10000,
"_source": [
"word_id",
"rank"
],
"track_total_hits": true
}
3.聚合语句
{
"query": {
"bool": {
"must": [
{
"range": {
"start_date": {
"lte": "2021-09-02T00:00:00"
}
}
},
{
"range": {
"end_date": {
"gte": "2021-09-02T00:00:00"
}
}
},
{
"terms": {
"app_id": [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
10000
]
}
}
]
}
},
"size": 0,
"aggs": {
"apps": {
"terms": {
"field": "app_id",
"collect_mode": "breadth_first",
"execution_hint": "map",
"size": 20
},
"aggs": {
"count_top3": {
"filter": {
"range": {
"rank": {
"lte": 3
}
}
}
}
}
}
}
}
优化思路
我们通过es创建拉链表、tendis进行最新记录的判断、可以极大的提高我们消费的过程,但是es当中随着数据量越来越大也会存在查询慢的问题。
我们可以把es分为冷热数据:热数据:最近两个月的数据 冷数据:历史数据(按月切割)
我们下一篇文档会讲到如何进行冷热数据迁移的自动化操作