上一篇我们说到如何通过拉链表的设计思路,使用es与tendis来快速的实现业务的需求,这节课我们讲下如何进行es冷热数据的自动化迁移
需求: 目前有谷歌、appstore的es库,我们需要按月进行迁移:当月1号开始创建迁移前一个月以及删除前两个月的数据任务
按月迁移方案
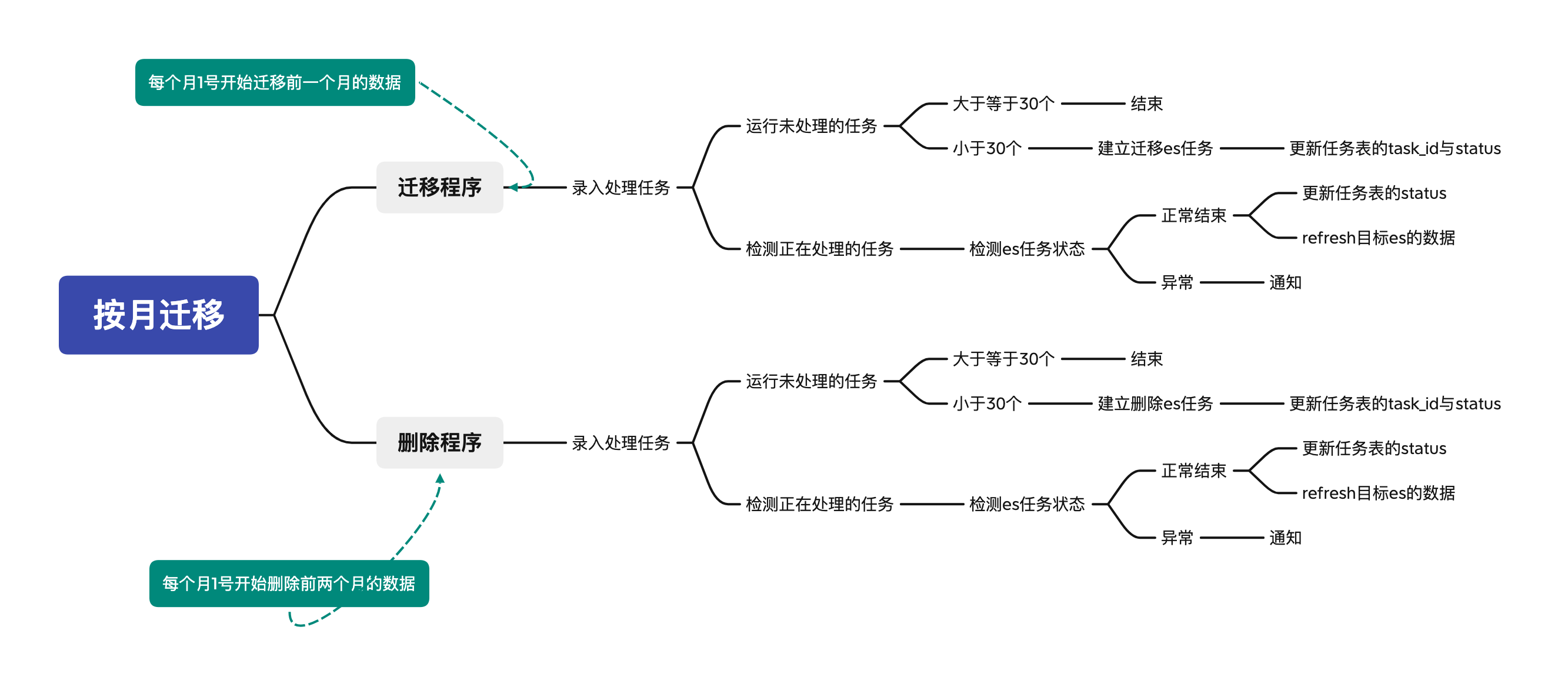
使用数据库进行任务的运行与检测
1.使用mysql作为任务列表
2.定时录入任务列表
3.运行与检测
1.mysql表结构说明
CREATE TABLE `es_word_task` (
`id` varchar(200) COLLATE utf8mb4_general_ci NOT NULL,
`time` varchar(20) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '日期:202108',
`start_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '开始时间',
`end_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '结束时间',
`updated_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`created_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`task_id` varchar(200) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '任务id',
`task_type` tinyint(4) NOT NULL DEFAULT '0' COMMENT '任务类型: 1.迁移数据 2.删除数据',
`status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '状态: 0.未处理 1.正在处理 2.处理成功',
`source` tinyint(4) NOT NULL DEFAULT '0' COMMENT '来源: 1.google 2.ios',
`dsl` json NOT NULL COMMENT '运行的脚本',
`es_index` varchar(255) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '' COMMENT '源es index',
PRIMARY KEY (`id`),
KEY `index_source_and_task_type_and_status` (`source`,`task_type`,`status`)
) ENGINE=XENGINE DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
2.录入表数据
1).录入迁移数据
sql: INSERT INTO es_word_task(id,time,start_time,end_time,task_type,source,dsl) VALUES(%(id)s,%(time)s,%(start_time)s,%(end_time)s,%(task_type)s,%(source)s,%(dsl)s)
id: google=> '%s_%s_%s_%s' % (source,country_id,time,task_type) ios=> '%s_%s_%s_%s_%s_%s' % (source,country_id,system_id,device_id,time,task_type)
time: '202108'
start_time: '2021-09-01 00:00:00'
end_time: '2021-09-30 23:59:59'
task_type: 1
source: 1.google 2.ios
dsl: 运行的脚本
2).录入删除任务数据
sql: INSERT INTO es_word_task(id,time,start_time,end_time,task_type,source,dsl,es_index) VALUES(%(id)s,%(time)s,%(start_time)s,%(end_time)s,%(task_type)s,%(source)s,%(dsl)s,%(es_index)s)
id: google=> '%s_%s_%s_%s' % (source,country_id,time,task_type) ios=> '%s_%s_%s_%s_%s_%s' % (source,country_id,system_id,device_id,time,task_type)
time: '202108'
start_time: '2021-09-01 00:00:00'
end_time: '2021-09-30 23:59:59'
task_type: 2
source: 1.google 2.ios
dsl: 运行的脚本
es_index: 需要删除的es_index
3.运行与检测
1).迁移任务
1.运行任务程序
1).先获取正在处理的程序
sql: SELECT COUNT(*) as count FROM es_word_task WHERE source=1 AND task_type=1 AND `status`=1
大于30 不处理
否则
sql: SELECT * FROM es_word_task WHERE source=1 AND task_type=1 AND `status`=0 limit (30-count)
查询语句,进行数据的迁移
dsl:
{
"source": {
"index": 'google_%s' % country_id, ## 源数据index
"remote": {
"host": "", # 源数据es地址
"socket_timeout": "50m",
"connect_timeout": "50m"
},
"size": 100000,
"query": {
"bool": {
"must": [{
"range": {
"start_date": {"lte": end_time} # end_time 格式化时间
}
}, {
"range": {
"end_date": {"gt": start_time} # start_time 格式化时间
}
}]}
}
},
"dest": {
"index": 'google_%s_%s' % (country_id, month)
}
}
async def reindex(country_id, month, start, end):
es = await AioESService.get('word_history')
body = dsl
return await es.reindex(body, wait_for_completion=False)
2).task_id录入以及状态的更新
从reindex得到的结果中得到task_id {'task': 'yeNKhCckS3ea_uswGpCGUg:158867532'}
sql: update es_word_task set task_id=%(task_id)s,status=1 where id=%(id)s
2.检测任务情况
1).获取当前正在处理的es任务
sql: SELECT * FROM es_word_task WHERE source=1 AND task_type=1 AND `status`=1
2).根据task_id去查询状态
url = '' # 源目标地址
res = requests.get('%s_tasks/%s' % (url, task_id))
data = res.json()
rate = round(data['task']['status']['batches']*100000 /
data['task']['status']['total']*100, 2) if data['task']['status']['total'] > 0 else 0
print(data['completed'], data['task']['status']['total'], data['task']['status']['batches'], rate,
data.get('response', {}).get('failures', []), re.findall(r'to(.*?)\[_doc\]', data['task']['description']))
当 data['completed']==True and data['task']['status']['batches']*100000 >= data['task']['status']['total'] 则任务结束
3).更新状态
sql: update es_word_task set status=2 where id=%(id)s
4).刷新目标es状态
async def refresh(country_id, month):
es = await AioESService.get('word_history')
res = await es.indices.refresh(index='google_%s_%s' % (country_id, month))
return res
2).删除任务
1.运行任务程序
1).获取正在处理的程序
sql: SELECT COUNT(*) as count FROM es_word_task WHERE source=1 AND task_type=2 AND `status`=1
大于30 不处理
否则
sql: SELECT * FROM es_word_task WHERE source=1 AND task_type=2 AND `status`=0 limit (30-count)
查询语句,进行数据的迁移
dsl:
{
"query": {
"bool": {
"must_not": [
{
"range": {
"end_date": {
"gt": end_time+1days # end_time需要format
}
}
}
]
}
}
}
es_index: 需要删除的es名称
async def delete(country_id):
body = dsl
es = await AioESService.get('word_back')
return await es.delete_by_query(
index=es_index, body=body, wait_for_completion=False, slices='auto'
)
2).task_id录入以及状态的更新
从reindex得到的结果中得到task_id {'task': 'yeNKhCckS3ea_uswGpCGUg:158867532'}
sql: update es_word_task set task_id=%(task_id)s,status=1 where id=%(id)s
2.检测任务情况
1).获取当前正在处理的es任务
sql: SELECT * FROM es_word_task WHERE source=1 AND task_type=2 AND `status`=1
2).根据task_id去查询状态
url = '' # 源目标地址
res = requests.get('%s_tasks/%s' % (url, task_id))
data = res.json()
print(data['completed'])
当 data['completed']==True 则任务结束
3.)更新状态
sql: update es_word_task set status=2 where id=%(id)s
4).刷新目标es状态
async def refresh(country_id, month):
es = await AioESService.get('word_back')
res = await es.indices.refresh(index='google_%s' % (country_id))
return res
THE END
至此一整个大数据存储方案的实现方案已经结束,如果大家有什么问题,欢迎与我联系。